
AIを使って株価を予測したい!
データを分析する手間を省きたい!
投資にあまり時間がかけられない!
上記のような方に向け、本記事では株価を予測する簡単なAIモデルをコード付きで紹介していきます。
ただ、本記事で紹介するのは完全なAIモデルではありません。
あくまでもベースとし、精度を上げるのは各々が取り組んでみてください。
また、作成の手順は「【保存版】AIを自分で一から作る方法|人工知能の作り方8ステップ」の流れに沿って説明していきます。

まだ読んでいない方は、この機会にぜひ読んでみてください。
Pythonで株価を予測するために必要な環境準備

今回はPythonで作成していくため、まずはPythonが実行可能な環境を準備します。
動けばなんでも良いですが、今回は「Google Colab」を用いてPythonを動かしていきます。
Google Colabとは?
Google社が提供している、ブラウザ上でPythonを動かすことのできるサービスのこと。
Pythonなどをインストールする必要がなく、誰でも無料ですぐに動かすことができます。
また、制限があるものの無料でGPUを使用できる点もメリット!
https://colab.research.google.com/?hl=ja
GPUを用いたほうが早く処理が完了するため、以下のコードで計算の際にGPUを使用できるようにしていきます。
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")また、Google Colab側でもGPUを使用できるようにします。
「ランタイム」のタブをクリックし、その中の「ランタイムのタイプを変更」をクリックします。
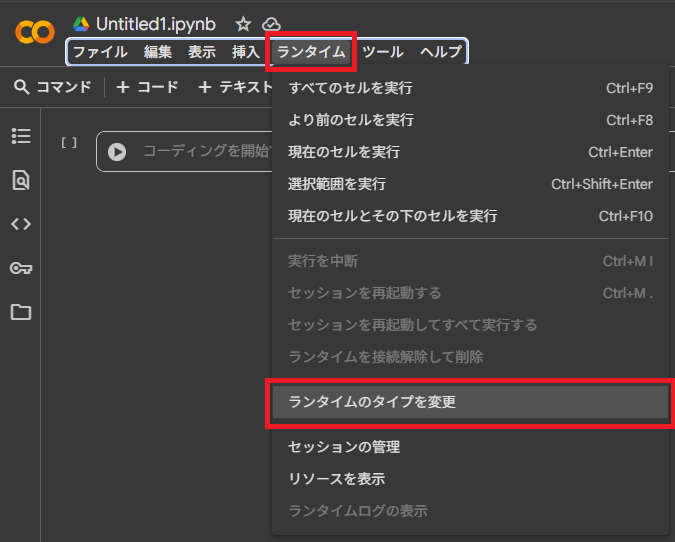
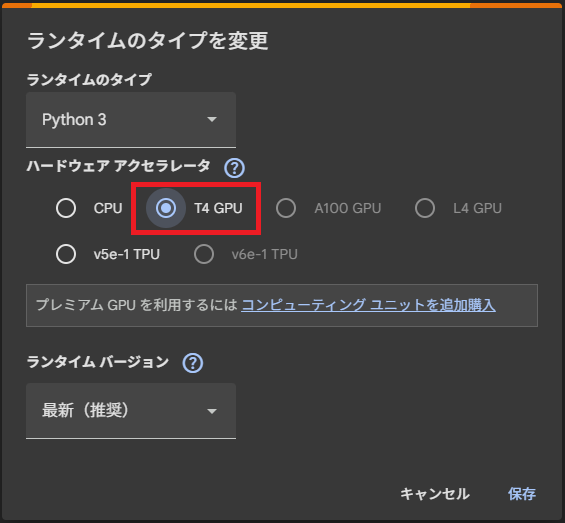
「CPU」→「T4 GPU」に変更し、「保存」をクリックして終了します。
AIを作成する目的や方針の決定

本記事のタイトルにもありますが、今回の目的は「株価を予測すること」です。
また、その「株価を予測すること」がゴールでもあります。
その点意識しながらAIを作成していきましょう。
株価を予測するために必要なデータの収集

先ほど決めた目的や方針をもとに、必要なデータを収集していきます。
さて、株価を予測するためには何が必要でしょうか。
ここで一度、自身が予測しているときに何をもとに予測しているか考えてみてください。
多くの人は過去の株価データをもとに予測しているかと思います。あるいは、決算の内容をもとに予測している人もいるかもしれません。
今回は比較的容易に集めやすい株価データを集めていきます。
ただ、人の手で過去の株価データを集めるのは非現実的ですし非効率です。
そこで手軽に取得できるのがyfinance!
yfinanceとは?
Yahoo!Financeから株価情報や財務データを簡単に取得できるPythonのライブラリのこと。
誰でも無料で利用することができます。
リアルタイムの株価を取得できるわけではないので、その点は注意しておきましょう。
yfinanceは様々な情報を得ることができますが、今回は「終値」を取得します。
また、「移動平均」も併せて計算していきます。
ticker = "7203.T" #証券コードの後ろに「.T」をつけることに注意
df = yf.download(ticker, start="2020-01-01", end="2025-09-01") #株価を取得したい期間を指定
df = df[["Close"]].dropna() #終値のみ抽出
# 移動平均の計算
df["MA5"] = df["Close"].rolling(window=5).mean()
df["MA25"] = df["Close"].rolling(window=25).mean()
df = df.dropna()株価を予測するために必要なデータの前処理

集めたデータをそのまま用いると予測精度は悪くなってしまいます。
というのも、銘柄によって株価は数十円~数万円と、スケールが大きく異なるためです。
それではうまく学習しきれず精度に大きく影響してしまいます。
そこで以下のような前処理を行います。
- 前日の株価との差を利用する
- 値を0~1の範囲に制限する(=正規化)
上記でスケールをそろえることができますから、精度は比較的よくなります。
# 正規化(すべての値を0~1の範囲に収める)
feature_scaler = MinMaxScaler()
target_scaler = MinMaxScaler()
features = df[["Close", "MA5", "MA25"]].values #入力対象のデータを指定
targets = df["Close"].values.reshape(-1, 1) #出力対象のデータを指定
scaled_features = feature_scaler.fit_transform(features) #入力対象データの正規化
scaled_targets = target_scaler.fit_transform(targets) #出力対象データの正規化
# LSTM用の系列データ作成(過去の〇個のデータを使用し次の1つの値を予測する学習用データセットを作成)
def create_sequences(data, target, seq_length=60):
X, y = [], []
for i in range(seq_length, len(data)): #seq_length, seq_length+1, seq_length+2, ..., len(data)
X.append(data[i-seq_length:i])
y.append(target[i])
return np.array(X), np.array(y) #array型としてXとyをそれぞれ返す
seq_length = 60 #60日間のデータをもとに次の値を予測
X, y = create_sequences(scaled_features, scaled_targets, seq_length)
# 学習用・検証用データに分割
split = int(len(X) * 0.8) #学習用データと検証用データを0.8:0.2の割合で分割
X_train, X_test = X[:split], X[split:]
y_train, y_test = y[:split], y[split:]
# PyTorch用に変換(GPUを用いて計算するため)
X_train = torch.tensor(X_train, dtype=torch.float32).to(device)
y_train = torch.tensor(y_train, dtype=torch.float32).to(device)
X_test = torch.tensor(X_test, dtype=torch.float32).to(device)
y_test = torch.tensor(y_test, dtype=torch.float32).to(device)株価を予測するAIモデルのアルゴリズムの選定

今回使用するアルゴリズムとしては「LSTM」を用います。
LSTMとは?
過去の出来事を覚えておき、次に何が起こるかを予測するもの。
株価のトレンドや周期性を学習することができることから株価予測によく用いられています。
また、LSTMは次のように定義されます。
# アルゴリズムの定義
class LSTMModel(nn.Module):
def __init__(self, input_size=3, hidden_size=512, num_layers=2):
super().__init__()
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, 1)
def forward(self, x):
out, _ = self.lstm(x)
return self.fc(out[:, -1, :])
model = LSTMModel().to(device)「def init(self, input_size=3, hidden_size=512, num_layers=2):」の部分について少し解説しますね。
- input_size
→入力時の特徴量数(今回は終値・5日移動平均・25日移動平均の3種類のため3と定義) - hidden_size
→隠れ層が持つ次元数(大きいほど複雑なパターンを記憶可能) - num_layers
→LSTMの層数(大きいほどより抽象的な特徴を学習可能)
Pythonで株価を予測するAIモデルの構築・学習

実際にAIモデルを構築し、加工したデータをもとに学習していきましょう!
必要なライブラリは以下の通りです。
import yfinance as yf
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error, mean_absolute_error
from torch.utils.data import TensorDataset, DataLoader
from torch.optim.lr_scheduler import ReduceLROnPlateau- yfinance
→Yahoo! Finance から株価データや企業情報を取得するためのライブラリ - numpy
→数値計算用のライブラリ - pandas
→表形式のデータを扱うライブラリ - matplotlib
→グラフを描画するためのライブラリ - scikit-learn
→機械学習に便利なツールが集まったライブラリ - PyTorch
→ディープラーニングのためのライブラリ
学習の前に損失関数や最適化関数の定義、学習率自動調節用のスケジューラを定義します。
# 学習の前処理
criterion = nn.MSELoss() #平均二乗誤差
optimizer = torch.optim.Adam(model.parameters(), lr=0.0009) #最適化関数
scheduler = ReduceLROnPlateau(optimizer, mode='min', factor=0.5, patience=5) #学習率調節用スケジューラ
train_loader = DataLoader(TensorDataset(X_train, y_train), batch_size=32, shuffle=True) #データローダーの定義以下が学習部分になります。
# 学習
for epoch in range(30): #30回学習を繰り返す
model.train() #学習モードに切り替え
total_loss = 0
for xb, yb in train_loader: #学習用データローダーからxとyの値を取り出す
output = model(xb) #モデルにxの値を入れた際の返り値を格納
loss = criterion(output, yb) #損失の計算
optimizer.zero_grad() #勾配のリセット
loss.backward() #勾配の計算
optimizer.step() #最適化関数によりパラメータの更新
total_loss += loss.item() #損失の蓄積
scheduler.step(total_loss) #全体損失をスケジューラに渡す
print(f"Epoch {epoch+1}, Loss: {total_loss/len(train_loader):.6f}") #エポック数ごとの損失を出力エポック数ごとの損失は以下のようになるかと思います。
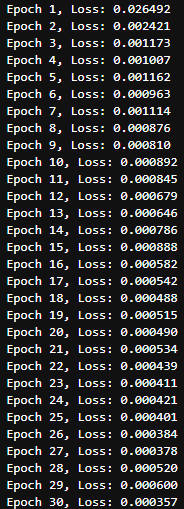
この程度の損失(Loss)であれば問題ありません。
Pythonで株価を予測するAIモデルの評価・改善

学習を終えたら、構築したAIモデルの精度がどのくらいかを調べていきます。
精度を調べるには、事前に分けた検証用のデータを用います。
また、精度の計算には以下を用います。
- MSE(平均二乗誤差)
→予測値と実測値の差を二乗して平均した値 - RMSE(平均平方根誤差)
→MSEの平方根をとった値 - MAE(平均絶対誤差)
→誤差の絶対値を平均した値。平均的に1株あたりどのくらいずれているかを表す指標 - MAPE(平均絶対パーセント誤差)
→予測が平均で何%ずれているかを表す指標
# 予測
model.eval()
with torch.no_grad(): #予測の場合は勾配を計算しない
predictions = model(X_test).cpu().numpy() #予測値をnumpy配列に変換(予測精度の計算のため)
actual = y_test.cpu().numpy() #株価をnumpy配列に変換
# 0~1にスケーリングしたものを戻す
predicted_prices = target_scaler.inverse_transform(predictions)
actual_prices = target_scaler.inverse_transform(actual)
# グラフ描画
plt.figure(figsize=(12, 6))
plt.plot(actual_prices, label="Actual") #実際の株価を描画
plt.plot(predicted_prices, label="Predicted", linestyle="--") #予測した株価を描画
plt.title(f"LSTM Stock Price Prediction (Close + MA5 + MA25) - {ticker}") #グラフのタイトルを指定
plt.xlabel("Time") #x軸のラベルを指定
plt.ylabel("Price (JPY)") #y軸のラベルを指定
plt.legend()
plt.show()
# 予測精度の計算
mse = mean_squared_error(actual_prices, predicted_prices)
rmse = np.sqrt(mse)
mae = mean_absolute_error(actual_prices, predicted_prices)
mape = np.mean(np.abs((actual_prices - predicted_prices) / (actual_prices + 1e-8))) * 100
print(f"MSE: {mse:.4f}")
print(f"RMSE: {rmse:.4f}")
print(f"MAE: {mae:.4f}")
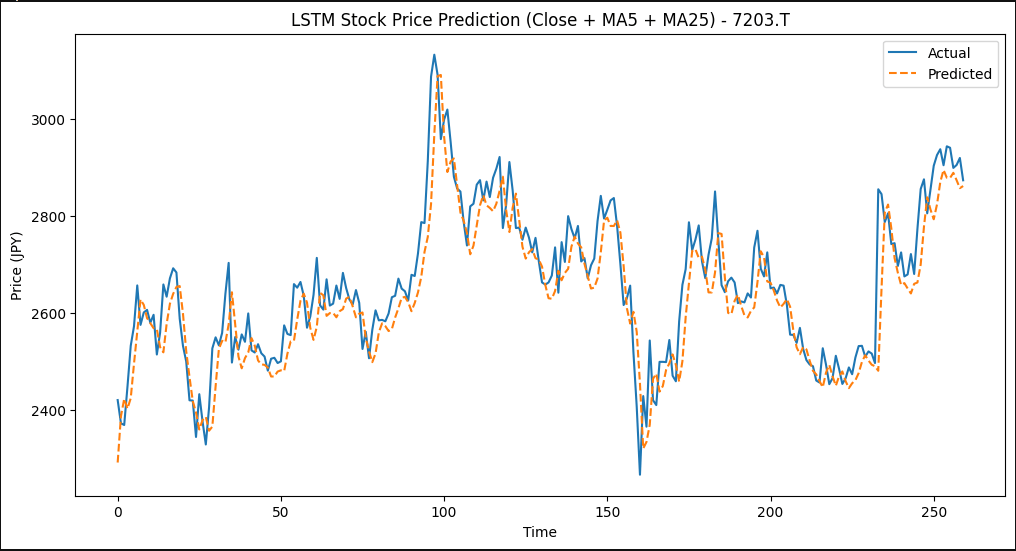
print(f"MAPE: {mape:.2f}%")グラフについては実測値(Actual)と予測値(Predicted)が同じような挙動をしていてば問題ありません。
大きく外れるようであれば、学習率を変えてみてください。
また、「MSE」「RMSE」「MAE」「MAPE」の値は以下のようになると思います。
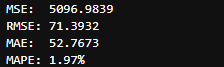
MAPEの値が5%以下であれば十分優れた精度ですが、10%や20%を超えるようであれば入力に出来高などを追加したりハイパーパラメータを調整したりしてみてください。
実際に株価を予測してみよう!

精度が問題ない程度になれば、実際に株価を予測していきます。
# 直近データから将来の株価を連続して予測するための関数定義
def predict_future(model, recent_data, days_to_predict=5):
model.eval() #推論モードに切り替え
predictions = [] #予測結果を格納
last_seq = recent_data[-seq_length:].copy() #最新のseq_length日分の特徴量を抽出
for _ in range(days_to_predict):
input_seq = torch.tensor(last_seq.reshape(1, seq_length, -1), dtype=torch.float32).to(device)
with torch.no_grad():
next_scaled = model(input_seq).item()
next_price = target_scaler.inverse_transform([[next_scaled]])[0, 0] #正規化された値をもとの株価に戻す
predictions.append(next_price) #予測株価を格納
# 新しい特徴量を構築(最新の株価と予測値からMA5とMA25を計算)
past_close = target_scaler.inverse_transform(last_seq[:, 0].reshape(-1, 1)).flatten()
closes = np.append(past_close, next_price)[-25:]
ma5 = np.mean(closes[-5:])
ma25 = np.mean(closes)
new_row = feature_scaler.transform([[next_price, ma5, ma25]])[0] #新しい特徴量を正規化
last_seq = np.vstack((last_seq[1:], new_row)) #last_seqの更新
return predictions #予測株価を返す
# 株価予測
future_prices = predict_future(model, scaled_features, days_to_predict=1) #翌日の株価のみ予測
predicted_next_day = future_prices[0] #翌日の株価を取り出す
print(f"予測された翌日の株価: {predicted_next_day:.2f} 円") #予測された株価の表示予測された株価をもとに投資するかどうか判断してみましょう!
Pythonで株価を予測するAIモデルの全体像

これまでのコードをまとめると以下のようになります。
時間がない人は以下のコードをそのままコピペしてみてください。
# 翌日の株価を予測するAIモデル
import yfinance as yf
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error, mean_absolute_error
from torch.utils.data import TensorDataset, DataLoader
from torch.optim.lr_scheduler import ReduceLROnPlateau
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 株価データの取得
ticker = "7203.T"
df = yf.download(ticker, start="2020-01-01", end="2025-09-01")
df = df[["Close"]].dropna()
# 移動平均の追加
df["MA5"] = df["Close"].rolling(window=5).mean()
df["MA25"] = df["Close"].rolling(window=25).mean()
df = df.dropna()
# 正規化(すべての値を0~1の範囲に収める)
feature_scaler = MinMaxScaler()
target_scaler = MinMaxScaler()
features = df[["Close", "MA5", "MA25"]].values
targets = df["Close"].values.reshape(-1, 1)
scaled_features = feature_scaler.fit_transform(features)
scaled_targets = target_scaler.fit_transform(targets)
# LSTM用の系列データ作成(過去の〇個のデータを使用し次の1つの値を予測する学習用データセットを作成)
def create_sequences(data, target, seq_length=60):
X, y = [], []
for i in range(seq_length, len(data)):
X.append(data[i-seq_length:i])
y.append(target[i])
return np.array(X), np.array(y)
seq_length = 60
X, y = create_sequences(scaled_features, scaled_targets, seq_length)
# 学習用・検証用データに分割
split = int(len(X) * 0.8)
X_train, X_test = X[:split], X[split:]
y_train, y_test = y[:split], y[split:]
# PyTorch用に変換
X_train = torch.tensor(X_train, dtype=torch.float32).to(device)
y_train = torch.tensor(y_train, dtype=torch.float32).to(device)
X_test = torch.tensor(X_test, dtype=torch.float32).to(device)
y_test = torch.tensor(y_test, dtype=torch.float32).to(device)
# モデルの定義
class LSTMModel(nn.Module):
def __init__(self, input_size=3, hidden_size=512, num_layers=2):
super().__init__()
self.lstm = nn.LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, 1)
def forward(self, x):
out, _ = self.lstm(x)
return self.fc(out[:, -1, :])
model = LSTMModel().to(device)
# 学習の前処理
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.0009)
scheduler = ReduceLROnPlateau(optimizer, mode='min', factor=0.5, patience=5)
train_loader = DataLoader(TensorDataset(X_train, y_train), batch_size=32, shuffle=True)
# 学習
for epoch in range(30):
model.train()
total_loss = 0
for xb, yb in train_loader:
output = model(xb)
loss = criterion(output, yb)
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_loss += loss.item()
scheduler.step(total_loss)
print(f"Epoch {epoch+1}, Loss: {total_loss/len(train_loader):.6f}")
# 予測
model.eval()
with torch.no_grad():
predictions = model(X_test).cpu().numpy()
actual = y_test.cpu().numpy()
# スケーリングを戻す
predicted_prices = target_scaler.inverse_transform(predictions)
actual_prices = target_scaler.inverse_transform(actual)
# グラフ描画
plt.figure(figsize=(12, 6))
plt.plot(actual_prices, label="Actual")
plt.plot(predicted_prices, label="Predicted", linestyle="--")
plt.title(f"LSTM Stock Price Prediction (Close + MA5 + MA25) - {ticker}")
plt.xlabel("Time")
plt.ylabel("Price (JPY)")
plt.legend()
plt.show()
# 予測精度
mse = mean_squared_error(actual_prices, predicted_prices)
rmse = np.sqrt(mse)
mae = mean_absolute_error(actual_prices, predicted_prices)
mape = np.mean(np.abs((actual_prices - predicted_prices) / (actual_prices + 1e-8))) * 100
print(f"MSE: {mse:.4f}")
print(f"RMSE: {rmse:.4f}")
print(f"MAE: {mae:.4f}")
print(f"MAPE: {mape:.2f}%")
# 株価予測
# 関数定義
def predict_future(model, recent_data, days_to_predict=5):
model.eval()
predictions = []
last_seq = recent_data[-seq_length:].copy()
for _ in range(days_to_predict):
input_seq = torch.tensor(last_seq.reshape(1, seq_length, -1), dtype=torch.float32).to(device)
with torch.no_grad():
next_scaled = model(input_seq).item()
next_price = target_scaler.inverse_transform([[next_scaled]])[0, 0]
predictions.append(next_price)
# 新しい特徴量を構築
past_close = target_scaler.inverse_transform(last_seq[:, 0].reshape(-1, 1)).flatten()
closes = np.append(past_close, next_price)[-25:]
ma5 = np.mean(closes[-5:])
ma25 = np.mean(closes)
new_row = feature_scaler.transform([[next_price, ma5, ma25]])[0]
last_seq = np.vstack((last_seq[1:], new_row))
return predictions
future_prices = predict_future(model, scaled_features, days_to_predict=1)
predicted_next_day = future_prices[0]
print(f"予測された翌日の株価: {predicted_next_day:.2f} 円")まとめ

さて、本記事ではPythonを用いて株価を予測するAIの作り方を紹介していきました!
どのような流れで行うかや、何が必要かは学んでもらえたかと思います。
ただ、本記事で紹介したAIは精度がまだまだ不十分です。
ベースは紹介したものでいいので、あとは自身で試行錯誤し、精度がより高いものを作り上げてみてください。


コメント